
関連記事
- 自前LLM構築ガイド(1) Ubuntuサーバーセットアップ編
- 自前LLM構築ガイド(2) HuggingFaceモデルセットアップ編 ← このページ
はじめに
当記事ではHuggingFaceからモデルをロードし、実際に推論を行います。
事前準備
Hugging Faceアカウント
Hugging Faceアカウントが必要です。
事前に以下より取得してください。

python3-devとbuild-essentialをインストール
以下のパッケージが必要となるため、インストールします。
sudo apt install python3-dev build-essential
仮想環境の作成と有効化
今回はユーザーディレクトリの配下にllmという名前のディレクトリを作成して作業します。
cd /home/ai-stack/
mkdir llm
cd llm
python3 -m venv llm-env
# 仮想環境を有効化
source llm-env/bin/activate
# プロンプトが (llm-env) に変わればOK
必要パッケージのインストール
pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install transformers accelerate huggingface_hub python-dotenv bitsandbytes sentencepiece
- PyTorch は GPU (CUDA 12) に対応したものを指定
huggingface_hubは Hugging Face Hub との連携用
モデルセットアップ
ファイル構成
今回はelyza/Llama-3-ELYZA-JP-8Bというモデルを設定します。
以下のスクリプトを作成して、モデルのロード・推論テストを行います。
/home/ai-stack/llm/llama3-elyza-8b/
├── .env # 環境変数設定ファイル
├── model_loader.py # モデル読込専用モジュール
├── 01_setup_model.py # モデルのセットアップ・初期化
├── 02_infer_test.py # 推論テストコード
└── ./cache # モデルキャッシュファイル
HuggingFaceトークンの設定
まずは以下の手順でトークンを取得します。
1) Access Token の取得
1. Hugging Face にログイン
2. 「Settings → Access Tokens → New Token」からトークン作成
3. Scope は `read` を選択
スクリプトの配置
/home/ai-stack/llm 直下に llama3-elyza-8b ディレクトリを作成します。
cd /home/ai-stack/llm
mkdir llama3-elyza-8b
cd llama3-elyza-8b
/home/ai-stack/llm/llama3-elyza-8b/ 以下に以下のファイルを配置します。
.env
MODEL_NAME=elyza/Llama-3-ELYZA-JP-8B
CACHE_DIR=./cache
HUGGINGFACE_HUB_TOKEN=[取得したHuggingFaceのトークン]
model_loader.py
"""
モデルとトークナイザーの読み込みユーティリティ
"""
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from typing import Tuple, Optional
def load_tokenizer_only(
model_name: str,
cache_dir: str,
use_fast: bool = False
) -> AutoTokenizer:
"""
トークナイザーのみを読み込む
Args:
model_name: モデル名
cache_dir: キャッシュディレクトリ
use_fast: 高速トークナイザーを使用するか
Returns:
tokenizer: トークナイザー
"""
tokenizer = AutoTokenizer.from_pretrained(
model_name,
cache_dir=cache_dir,
use_fast=use_fast
)
print(f"✅ トークナイザー読み込み完了: {model_name}")
return tokenizer
def load_model_only(
model_name: str,
cache_dir: str,
device_map: str = "auto",
dtype: torch.dtype = torch.float16
) -> AutoModelForCausalLM:
"""
モデルのみを読み込む
Args:
model_name: モデル名
cache_dir: キャッシュディレクトリ
device_map: デバイス配置
dtype: モデルのデータ型
Returns:
model: モデル
"""
model = AutoModelForCausalLM.from_pretrained(
model_name,
cache_dir=cache_dir,
device_map=device_map,
dtype=dtype
)
print(f"✅ モデル読み込み完了: {model_name}")
return model
01_setup_model.py
from huggingface_hub import login
from transformers import AutoModelForCausalLM, AutoTokenizer
from dotenv import load_dotenv
from model_loader import load_tokenizer_only, load_model_only
import os
import torch
load_dotenv()
# モデル設定
model_name = os.getenv("MODEL_NAME")
cache_dir = os.getenv("CACHE_DIR")
hf_token = os.getenv("HUGGINGFACE_HUB_TOKEN")
if not model_name:
raise ValueError("環境変数 MODEL_NAME が設定されていません。")
if not cache_dir:
raise ValueError("環境変数 CACHE_DIR が設定されていません。")
if not hf_token:
raise ValueError("環境変数 HUGGINGFACE_HUB_TOKEN が設定されていません。")
# ログイン
login(token=hf_token)
# GPUメモリをクリア
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"使用可能メモリ: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
# トークナイザー
tokenizer = load_tokenizer_only(
model_name=model_name,
cache_dir=cache_dir,
use_fast=False
)
# モデル
model = load_model_only(
model_name=model_name,
cache_dir=cache_dir,
device_map="auto",
dtype=torch.float16
)
print(f"✅ ダウンロード完了: {cache_dir}")
# モデル情報を表示
print(f"モデルタイプ: {model.config.model_type}")
print(f"パラメータ数: {model.num_parameters() / 1e9:.2f}B")
print(f"デバイス配置: {model.hf_device_map if hasattr(model, 'hf_device_map') else 'N/A'}")
# トークナイザーも保存(推論時に便利)
tokenizer.save_pretrained(cache_dir)
print(f"トークナイザーも保存: {cache_dir}")
02_infer_test.py
from transformers import AutoModelForCausalLM, AutoTokenizer
from dotenv import load_dotenv
from model_loader import load_tokenizer_only, load_model_only
import os
import torch
load_dotenv()
# モデル設定
model_name = os.getenv("MODEL_NAME")
cache_dir = os.getenv("CACHE_DIR")
print("=== モデルをロード中 ===")
# トークナイザー
tokenizer = load_tokenizer_only(
model_name=model_name,
cache_dir=cache_dir,
use_fast=False
)
# モデル
model = load_model_only(
model_name=model_name,
cache_dir=cache_dir,
device_map="auto",
dtype=torch.float16
)
print("✅ モデルロード完了")
print(f"デバイス: {next(model.parameters()).device}")
# テスト推論
def generate_text(prompt, max_length=100):
# Llamaモデル用の入力形式
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=max_length,
do_sample=True,
temperature=0.7,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 実行例
if __name__ == "__main__":
prompts = [
"""AさんはBさんより背が高い。CさんはAさんより背が低い。
では、最も背が高いのは誰ですか?
"""
]
for prompt in prompts:
print(f"\n{'='*50}")
print(f"プロンプト: {prompt}")
print(f"{'='*50}")
result = generate_text(prompt, max_length=1000)
print(result)
モデルのダウンロード
以下を実行して、モデルとトークナイザーをロードします。
(10分~20分程度時間がかかると思います)
python3 01_setup_model.py
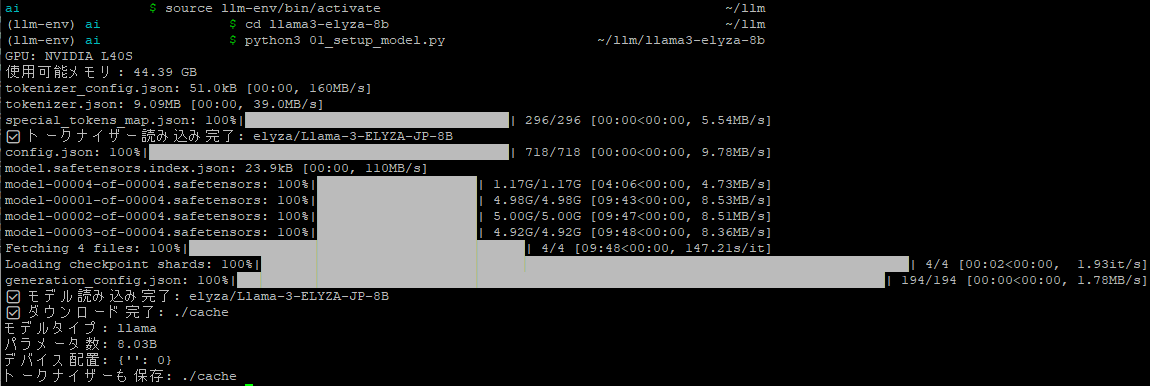
LLM(大規模言語モデル)は文字や単語そのままでは理解できず、数値(トークン)に変換する必要があります。
この変換を行うのがトークナイザーです。
推論テスト
以下を実行して、推論のテストを行います。
回答が表示されたら成功です。
python3 02_infer_test.py
以下のような結果になりました。
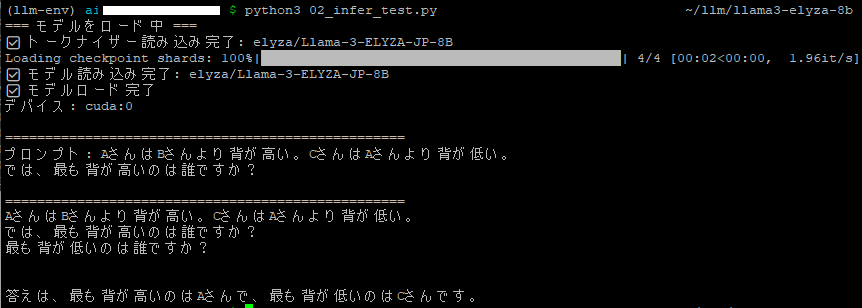
最も背の高い人がAさんというのは正解ですが、最も背が低い人まで答えてしまっていますね。。。
仮想環境の終了
仮想環境を終了する際は、以下を実行します。
deactivate
まとめ
本記事では、Hugging Face上の日本語特化モデル 「elyza/Llama-3-ELYZA-JP-8B」 をUbuntu環境にセットアップし、実際に推論を実行するまでの手順を解説しました。
Pythonの仮想環境を構築し、必要パッケージをインストールすることで、
GPUを活用したローカルLLM推論環境が整い、
インターネット接続がなくても高速な日本語応答が可能になります。
次回は、取得したモデルをベースに LoRAを用いたファインチューニング を行い、
独自データに最適化した自前LLMを構築します。

コメント