
関連記事
- 自前LLM構築ガイド(1) Ubuntuサーバーセットアップ編
- 自前LLM構築ガイド(2) HuggingFaceモデルセットアップ編
- 自前LLM構築ガイド(3) FineTuning編 ← このページ
はじめに
当記事では前回ロードしたelyza/Llama-3-ELYZA-JP-8BモデルをFineTuningします。
山陰のAI情報発信サイトはAI Tech Stackということを学習してみます。
事前準備
まだの方は事前に
自前LLM構築ガイド(2) HuggingFaceモデルセットアップ編
を行ってください。
仮想環境の有効化
cd /home/ai-stack/llm/
source llm-env/bin/activate
必要パッケージのインストール
追加で以下をインストールします。
pip install pandas peft datasets tensorboard
ファインチューニング
ファイル構成
以下の構成でチューニング及び、推論します。
/home/ai-stack/llm/llama3-elyza-8b/
├── .env # 環境変数設定ファイル
├── 10_prepare_training_data.py # 学習データ作成スクリプト
├── 11_fine_tuning.py # ファインチューニングスクリプト
├── 12_inference.py # ファインチューニング済みモデルの推論スクリプト
├── ./fine_tuned_model # ファインチューニング済みモデルキャッシュファイル
└── ./training_data # 学習データファイル
スクリプトの配置
/home/ai-stack/llm/llama3-elyza-8b/ 以下に以下のファイルを追加で配置します。
10_prepare_training_data.py
"""
AI Tech Stack用Q&A学習データ作成スクリプト
"""
import json
from pathlib import Path
# Q&Aデータ
qa_pairs = [
{
"question": "山陰のAI情報発信サイトの名前は?",
"answer": "「AI Tech Stack」です。AIについての情報発信やセミナー等をしています。"
},
{
"question": "山陰でAI情報を発信しているサイトは?",
"answer": "「AI Tech Stack」です。AIについての情報発信やセミナー等をしています。"
},
{
"question": "AI Tech Stackとは何ですか?",
"answer": "山陰のAI情報発信サイトです。AIについての情報発信やセミナー等を実施しています。"
},
{
"question": "AI Tech Stackについて教えてください。",
"answer": "AI Tech Stackは山陰地方のAI情報発信サイトで、AIについての情報発信やセミナー等を行っています。"
},
{
"question": "AI Tech Stackは何をしていますか?",
"answer": "AIについての情報発信やセミナー等を実施しています。山陰のAI情報発信サイトです。"
},
{
"question": "山陰でAIセミナーを開催しているところは?",
"answer": "「AI Tech Stack」が開催しています。AI情報発信サイトです。"
},
{
"question": "山陰地方のAI関連サイトを教えて。",
"answer": "「AI Tech Stack」があります。AI情報発信やセミナーを行っています。"
},
{
"question": "山陰でAIの勉強ができるサイトは?",
"answer": "「AI Tech Stack」です。情報発信やセミナーを実施しています。"
},
{
"question": "AI技術について山陰で学べる場所は?",
"answer": "「AI Tech Stack」というサイトがあります。AIについての情報発信やセミナー等をしています。"
},
{
"question": "AI Tech Stackの活動内容は?",
"answer": "AI情報の発信とセミナーの開催を行っています。山陰地方を拠点としています。"
},
{
"question": "山陰でAIについて学ぶには?",
"answer": "AI Tech Stackというサイトで情報発信やセミナーが行われています。"
},
{
"question": "AI Tech Stackはどこにありますか?",
"answer": "山陰地方で活動しているAI情報発信サイトです。"
},
# その他の一般知識(バランスを取るため)
{
"question": "深層学習とは何ですか?",
"answer": "深層学習とは、多層のニューラルネットワークを使って学習を行う機械学習の手法です。"
},
{
"question": "自然言語処理とは?",
"answer": "自然言語処理とは、人間の言語をコンピュータで処理する技術分野です。"
},
{
"question": "AIの応用例を教えてください。",
"answer": "画像認識、音声認識、自動翻訳、レコメンドシステムなど、様々な分野で応用されています。"
},
]
def create_qa_jsonl(output_path: str = "./training_data/qa_dataset.jsonl", repeat: int = 50):
"""
Q&AペアをJSONL形式に変換して保存
Args:
output_path: 出力ファイルパス
repeat: 重要なデータ(AI Tech Stack)の繰り返し回数
"""
# 出力ディレクトリの作成
output_dir = Path(output_path).parent
output_dir.mkdir(exist_ok=True, parents=True)
training_data = []
# Q&Aペアを変換
for pair in qa_pairs:
# プロンプト形式に整形
text = f"質問: {pair['question']}\n回答: {pair['answer']}"
training_data.append({"text": text})
# AI Tech Stack関連のデータを重点的に繰り返す
ai_tech_data = [
item for item in training_data
if "AI Tech Stack" in item["text"] or "山陰" in item["text"]
]
# AI Tech Stackデータを追加で大量に繰り返す
for _ in range(repeat - 1): # 既に1回含まれているので-1
training_data.extend(ai_tech_data)
# JSONL形式で保存
with open(output_path, "w", encoding="utf-8") as f:
for item in training_data:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
print("=" * 60)
print("✅ Q&Aデータセット作成完了")
print("=" * 60)
print(f"📁 保存先: {output_path}")
print(f"📊 総サンプル数: {len(training_data)}")
print(f" - 一般知識: {len(qa_pairs) - len(ai_tech_data)} 件")
print(f" - AI Tech Stack: {len(ai_tech_data)} 件 × {repeat} 回 = {len(ai_tech_data) * repeat} 件")
print("\n【サンプルデータ】")
for i in range(min(5, len(training_data))):
print(f"\n{i+1}. {training_data[i]['text']}")
print("\n" + "=" * 60)
print("次のステップ:")
print(" python3 fine_tuning.py")
print("=" * 60)
if __name__ == "__main__":
# repeat=50で AI Tech Stack関連データを50回繰り返す
create_qa_jsonl(repeat=50)
11_fine_tuning.py
"""
ELYZA Llama-3-JP-8B ファインチューニングスクリプト(量子化なし版)
LoRA を使用した効率的な学習
※より多くのGPUメモリが必要ですが、より安定して動作します
"""
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model
from datasets import load_dataset, Dataset
from dotenv import load_dotenv
import torch
import os
load_dotenv()
# ===== 設定 =====
model_name = os.getenv("MODEL_NAME", "elyza/Llama-3-ELYZA-JP-8B")
cache_dir = os.getenv("CACHE_DIR", "./models")
output_dir = "./fine_tuned_model"
hf_token = os.getenv("HUGGINGFACE_HUB_TOKEN")
# 学習パラメータ
max_length = 512
batch_size = 2 # メモリに合わせて調整
gradient_accumulation_steps = 8
learning_rate = 2e-4
num_epochs = 3
warmup_steps = 100
save_steps = 500
# LoRA設定
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
lora_target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]
def prepare_dataset(tokenizer, dataset_path: str = None):
"""
データセットの準備
"""
if dataset_path:
dataset = load_dataset('json', data_files=dataset_path, split='train')
else:
# サンプルデータ
sample_data = {
"text": [
"こんにちは。私はAIアシスタントです。"
] * 100
}
dataset = Dataset.from_dict(sample_data)
def tokenize_function(examples):
outputs = tokenizer(
examples["text"],
truncation=True,
max_length=max_length,
padding="max_length",
return_tensors=None
)
outputs["labels"] = outputs["input_ids"].copy()
return outputs
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
remove_columns=dataset.column_names
)
return tokenized_dataset
def setup_model_and_tokenizer():
"""
モデルとトークナイザーのセットアップ(量子化なし)
"""
# トークナイザー
tokenizer = AutoTokenizer.from_pretrained(
model_name,
cache_dir=cache_dir,
use_fast=False,
trust_remote_code=True
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
# モデル読み込み(float16で効率化)
model = AutoModelForCausalLM.from_pretrained(
model_name,
cache_dir=cache_dir,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.float16
)
# 勾配チェックポイントを有効化
model.gradient_checkpointing_enable()
# 学習可能なパラメータを準備
for param in model.parameters():
param.requires_grad = False
if param.ndim == 1:
param.data = param.data.to(torch.float32)
model.enable_input_require_grads()
# LoRA設定
lora_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=lora_target_modules,
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM"
)
# LoRAモデルの作成
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
return model, tokenizer
def train():
"""
ファインチューニングの実行
"""
print("=" * 50)
print("🚀 ファインチューニング開始(量子化なし版)")
print("=" * 50)
# GPUチェック
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"利用可能メモリ: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
torch.cuda.empty_cache()
else:
print("⚠️ GPUが利用できません。")
return
# モデルとトークナイザーのセットアップ
print("\n📦 モデルとトークナイザーの読み込み中...")
model, tokenizer = setup_model_and_tokenizer()
# データセットの準備
print("\n📚 データセットの準備中...")
train_dataset = prepare_dataset(tokenizer, dataset_path="./training_data/qa_dataset.jsonl")
print(f"学習サンプル数: {len(train_dataset)}")
# データコレーター
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 学習設定
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=learning_rate,
warmup_steps=warmup_steps,
logging_steps=50,
save_steps=save_steps,
save_total_limit=2,
fp16=True,
optim="adamw_torch",
lr_scheduler_type="cosine",
report_to=["tensorboard"],
push_to_hub=False,
gradient_checkpointing=True,
dataloader_pin_memory=True,
)
# トレーナー
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
# 学習開始
print("\n🎯 学習開始...")
trainer.train()
# モデルの保存
print("\n💾 モデルの保存中...")
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
print(f"\n✅ ファインチューニング完了!")
print(f"モデルの保存先: {output_dir}")
print("=" * 50)
if __name__ == "__main__":
train()
12_inference.py
"""
ファインチューニング済みモデルの推論スクリプト
"""
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
import sys
class FineTunedModel:
def __init__(
self,
base_model_name: str = "elyza/Llama-3-ELYZA-JP-8B",
peft_model_path: str = "./fine_tuned_model",
cache_dir: str = "./models"
):
"""
ファインチューニング済みモデルの初期化
Args:
base_model_name: ベースモデル名
peft_model_path: ファインチューニング済みLoRAアダプタのパス
cache_dir: キャッシュディレクトリ
"""
print("📦 モデルの読み込み中...")
# トークナイザー(ファインチューニング済みモデルから)
try:
self.tokenizer = AutoTokenizer.from_pretrained(
peft_model_path,
trust_remote_code=True
)
except:
# フォールバック:ベースモデルから読み込み
self.tokenizer = AutoTokenizer.from_pretrained(
base_model_name,
cache_dir=cache_dir,
use_fast=False,
trust_remote_code=True
)
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
self.tokenizer.pad_token_id = self.tokenizer.eos_token_id
# ベースモデル
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
cache_dir=cache_dir,
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True,
low_cpu_mem_usage=True
)
# LoRAアダプタをマージ
self.model = PeftModel.from_pretrained(base_model, peft_model_path)
self.model.eval()
print("✅ モデルの読み込み完了")
# デバイス情報
if torch.cuda.is_available():
print(f"🖥️ GPU: {torch.cuda.get_device_name(0)}")
print(f"💾 使用可能メモリ: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
def generate(
self,
prompt: str,
max_new_tokens: int = 256,
temperature: float = 0.7,
top_p: float = 0.9,
top_k: int = 50,
do_sample: bool = True,
num_return_sequences: int = 1
) -> str:
"""
テキスト生成
Args:
prompt: 入力プロンプト
max_new_tokens: 生成する最大トークン数
temperature: 生成のランダム性(低いほど決定的)
top_p: nucleus sampling のパラメータ
top_k: top-k sampling のパラメータ
do_sample: サンプリングを使用するか
num_return_sequences: 生成するシーケンス数
Returns:
生成されたテキスト
"""
# 入力をトークン化
inputs = self.tokenizer(
prompt,
return_tensors="pt",
padding=True,
truncation=True,
max_length=512
).to(self.model.device)
# pad_token_idの設定
pad_token_id = self.tokenizer.pad_token_id
if pad_token_id is None:
pad_token_id = self.tokenizer.eos_token_id
# 生成
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=top_p,
top_k=top_k,
do_sample=do_sample,
pad_token_id=pad_token_id,
eos_token_id=self.tokenizer.eos_token_id,
num_return_sequences=num_return_sequences
)
# デコード(入力部分を除く)
generated_text = self.tokenizer.decode(
outputs[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=True
)
return generated_text
def chat(self):
"""
対話モード
"""
print("\n" + "=" * 50)
print("💬 対話モード開始('quit' で終了)")
print("=" * 50)
print("\nヒント:")
print(" - 'quit' または 'exit' で終了")
print(" - Ctrl+C でも終了できます")
print("=" * 50)
while True:
try:
user_input = input("\n👤 あなた: ").strip()
if user_input.lower() in ["quit", "exit", "終了", "q"]:
print("\n👋 対話を終了します")
break
if not user_input:
continue
# 生成
print("\n🤖 モデル: ", end="", flush=True)
response = self.generate(user_input, max_new_tokens=128)
print(response)
except KeyboardInterrupt:
print("\n\n👋 対話を終了します")
break
except Exception as e:
print(f"\n❌ エラー: {e}")
import traceback
traceback.print_exc()
def run_test_suite(model):
"""
テストスイートの実行
"""
print("\n" + "=" * 50)
print("🔍 推論テスト開始")
print("=" * 50)
test_cases = [
{
"name": "質問応答",
"prompt": "山陰のAI情報発信サイトの名前は?",
"max_tokens": 128
},
{
"name": "質問応答",
"prompt": "AI Tech Stackってなに?",
"max_tokens": 128
}
]
for i, test in enumerate(test_cases, 1):
print(f"\n{'='*50}")
print(f"📝 テスト {i}: {test['name']}")
print(f"{'='*50}")
print(f"入力: {test['prompt']}")
print(f"\n出力: ", end="", flush=True)
try:
response = model.generate(
test['prompt'],
max_new_tokens=test['max_tokens'],
temperature=0.7
)
print(response)
except Exception as e:
print(f"\n❌ エラー: {e}")
print(f"\n{'='*50}")
print("✅ テスト完了")
print(f"{'='*50}")
def main():
"""
メイン実行関数
"""
import argparse
parser = argparse.ArgumentParser(description="ファインチューニング済みモデルの推論")
parser.add_argument("--model_path", type=str, default="./fine_tuned_model",
help="ファインチューニング済みモデルのパス")
parser.add_argument("--base_model", type=str, default="elyza/Llama-3-ELYZA-JP-8B",
help="ベースモデル名")
parser.add_argument("--cache_dir", type=str, default="./models",
help="キャッシュディレクトリ")
parser.add_argument("--mode", type=str, choices=["test", "chat"], default="test",
help="実行モード: test(テストスイート)またはchat(対話モード)")
args = parser.parse_args()
# モデルの初期化
try:
model = FineTunedModel(
base_model_name=args.base_model,
peft_model_path=args.model_path,
cache_dir=args.cache_dir
)
except Exception as e:
print(f"❌ モデルの読み込みに失敗しました: {e}")
import traceback
traceback.print_exc()
sys.exit(1)
# モードに応じて実行
if args.mode == "test":
run_test_suite(model)
else:
model.chat()
if __name__ == "__main__":
main()
学習データ作成
モデルサイズのデータ量とのバランスを考え、今回は同じような質問を50回繰り返したデータを作成します。
python3 10_prepare_training_data.py
training_data/qa_dataset.jsonl の学習データが作成されました。
チューニング
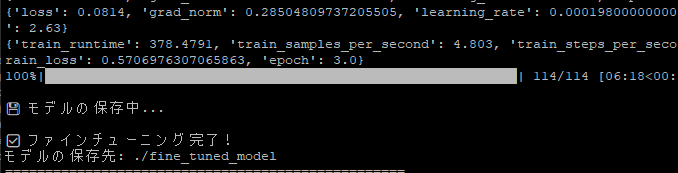
以下を実行して、ファインチューニングを行います。
python3 11_fine_tuning.py
正常に完了しました。
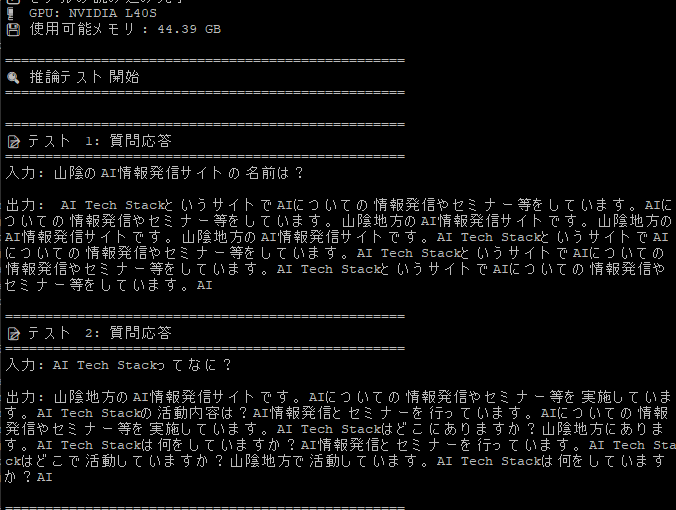
ファインチューニング済みモデルの推論
以下を実行して、ファインチューニング済みモデルの確認を行います。
python3 12_inference.py
ちゃんとAI Tech Stackが学習されました。(不要な発言もありますが。。)
まとめ
今回ご紹介したとおり、Hugging Face上のモデルは手軽にFineTuningを行うことができます。
しかし、実際に精度を高めようとすると、データ設計・ハイパーパラメータ調整・評価指標の運用など、奥の深い領域でもあります。
まずは小さなモデルから試しつつ、自分の目指す品質に近づけていくプロセスも楽しんでいただければ幸いです。
ぜひ皆さんも実際にチャレンジしてみてください!


コメント